https://mcode.co.kr/video/list2?viewMode=view&idx=92
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
메타코드로부터 제공받은 강의를 바탕으로 후기를 작성하고 있습니다.


웹 크롤링을 시작하기 전에, 가장 먼저 해야 할 일은 해당 사이트의 크롤링 규정을 확인하는 것입니다.
이 스크린샷에서는 robots.txt 파일을 통해 사이트 규정을 어떻게 확인하는지 보여드립니다.
우리가 존중해야 할 웹의 에티켓이자, 웹 크롤링의 첫 걸음입니다.
코드는 우선 우리가 사용할것들 위주로 먼저 import합니다!

웹 페이지에는 종종 데이터가 표 형태로 제공됩니다.
Python의 Beautiful Soup 라이브러리를 사용하여 특정 태그를 식별하고, 전체 테이블 또는 특정 행과 열에 위치한 데이터를 효율적으로 추출하는 방법을 배울 수 있습니다.
wendriver를 활용하는것을 확인 할 수 있는 코드입니다.

가끔 원하는 텍스트를 추출하는 데 실패할 수 있습니다.
이러한 상황에서는 동적 웹 페이지의 경우 Selenium과 같은 도구를 사용하여 실시간으로 페이지를 로드하고 데이터를 추출하는 방법을 배울 수 있습니다
크롬에서 개발자 모드에 들어가서 구조에 대해서 한번 더 확인합니다!
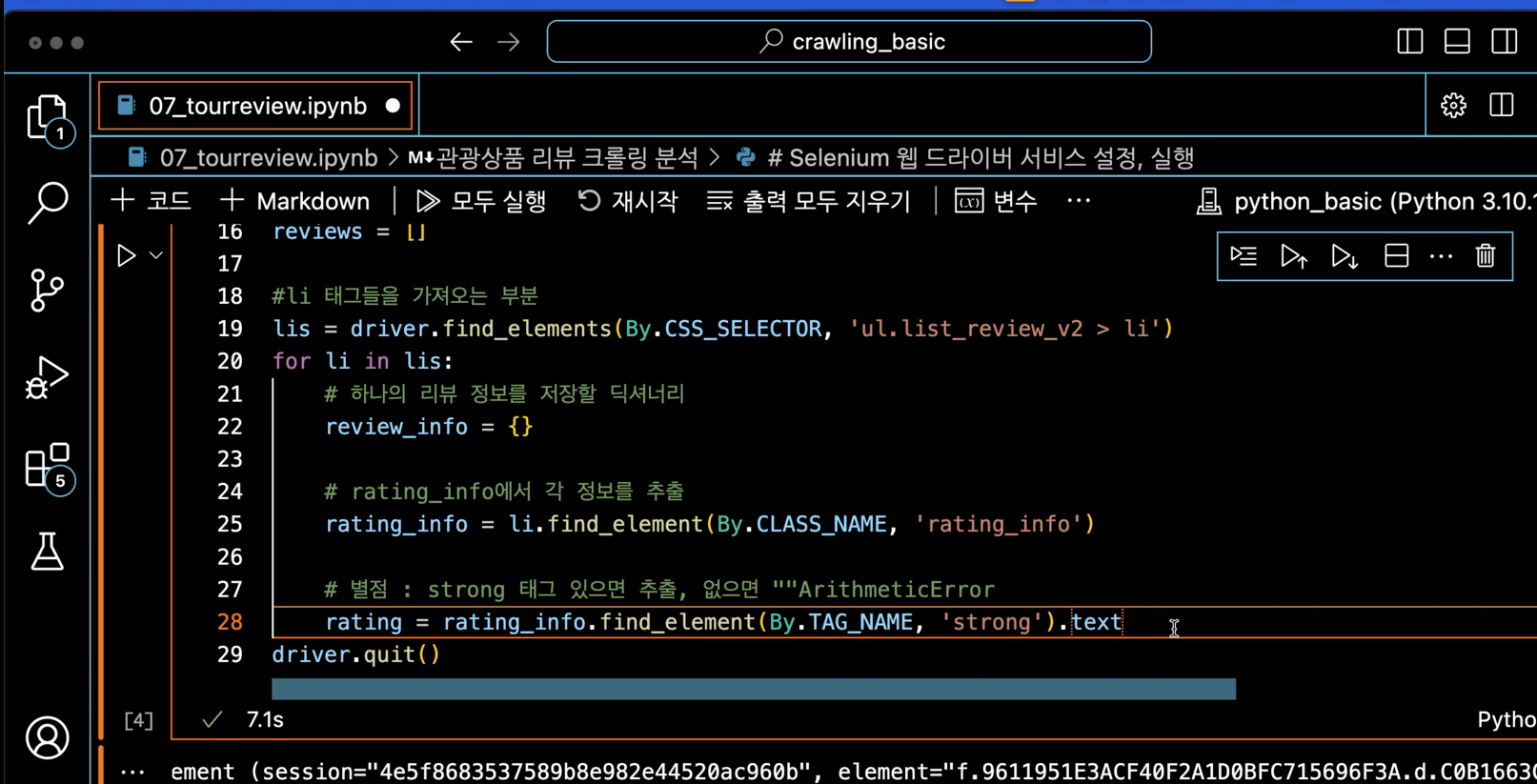
웹 페이지의 구조가 변경되거나 예상치 못한 이유로 특정 태그를 찾을 수 없는 경우가 있습니다.
이때 CSS 선택자, XPath 또는 정규 표현식을 사용하여 원하는 데이터를 위치시키는 효과적인 방법을 배울 수 있습니다.
현재 우리가 보는 강의는 XPath를 사용하여 테그를 찾는 방법을 많이 쓰고 있습니다.
기회가 된다면 다른 방법에 대해서도 공부하고 싶어요!

성공적으로 데이터를 크롤링한 후, 다음 단계는 데이터를 저장하고 분석하는 것입니다. 크롤링한 데이터를 딕셔너리 형태로 저장하는 방법과 Python의 Pandas 라이브러리를 사용하여 데이터를 조직하고 분석하는 방법을 배울 수 있습니다.
이 강의를 통해 웹 크롤링의 기본을 배우고 실제 상황에서 다양한 상황을 처리하는 방법을 익혔기를 바랍니다. 웹 크롤링은 데이터 기반 의사결정 과정에서 중요한 역할을 합니다. 이번 강의가 웹에서 필요한 정보를 자유롭게 수집하고 활용하는 데 도움이 되었기를 바랍니다.

크롤링 데이터의 윤리적 사용
- 데이터 접근 정책 준수: 크롤링할 웹사이트의 robots.txt 파일과 이용 약관을 확인하여 윤리적으로 데이터를 수집하세요.
- 개인정보 보호: 수집한 데이터 중 개인정보가 포함되어 있다면, 해당 정보를 보호하고, 사용 전 반드시 사용자의 동의를 받으세요.
- 데이터 사용 목적 명확화: 수집한 데이터를 사용할 때는 그 목적을 분명히 하고, 부적절한 용도로 사용하지 않도록 주의하세요.



