https://mcode.co.kr/video/list2?viewMode=view&idx=92
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr

BeautifulSoup에 대한 소개
BeautifulSoup은 Python으로 웹 데이터를 크롤링하고 파싱하는 데 사용되는 라이브러리입니다. HTML과 XML 파일에서 데이터를 추출하기 위해 사용되며, 웹 스크래핑에 매우 유용한 도구입니다. BeautifulSoup을 사용하면 복잡한 HTML 문서에서 데이터를 쉽게 찾고, 추출하고, 조작할 수 있습니다.

BeautifulSoup의 기본 사용법
- 라이브러리 설치: BeautifulSoup과 함께 requests 모듈을 사용하여 HTTP 요청을 보내고 받은 페이지의 내용을 파싱합니다. 먼저, pip install beautifulsoup4와 pip install requests를 통해 필요한 라이브러리를 설치해야 합니다.
- 기본 구조: BeautifulSoup 모듈을 bs4 라이브러리에서 임포트하고, requests 모듈을 사용하여 웹 페이지의 HTML을 가져온 후, BeautifulSoup 객체를 생성하여 HTML을 파싱합니다.

BeautifulSoup의 주요 기능
- HTML 탐색 및 검색: BeautifulSoup은 HTML 문서를 탐색하고 검색하는 데 사용됩니다. soup 객체를 사용하여 HTML 요소에 접근하고, soup.title.get_text() 또는 soup.title.string과 같은 메소드를 사용하여 텍스트를 추출할 수 있습니다.
- 데이터 추출: BeautifulSoup을 사용하면 HTML 문서에서 원하는 데이터를 쉽게 추출할 수 있습니다. 예를 들어, 특정 태그의 내용이나 속성 값을 가져오는 것이 가능합니다.

수업 코드 예시
시작은 원래 쉬우나 생각없이 듣고 있으면 다시 수강해야 하는 경우도 있음.
주의하고 집중하길 바랍니다.

robots.txt 파일에 대한 이해
robots.txt 파일은 웹사이트를 방문하는 웹 크롤러(봇)에게 어떤 페이지를 크롤링해도 되고, 어떤 페이지는 크롤링해서는 안 되는지 지시하는 역할을 하는 텍스트 파일입니다. 이 파일은 웹사이트의 루트 디렉토리에 위치하며, 검색 엔진 최적화(SEO)와 사이트의 효율적인 관리에 중요한 역할을 합니다.
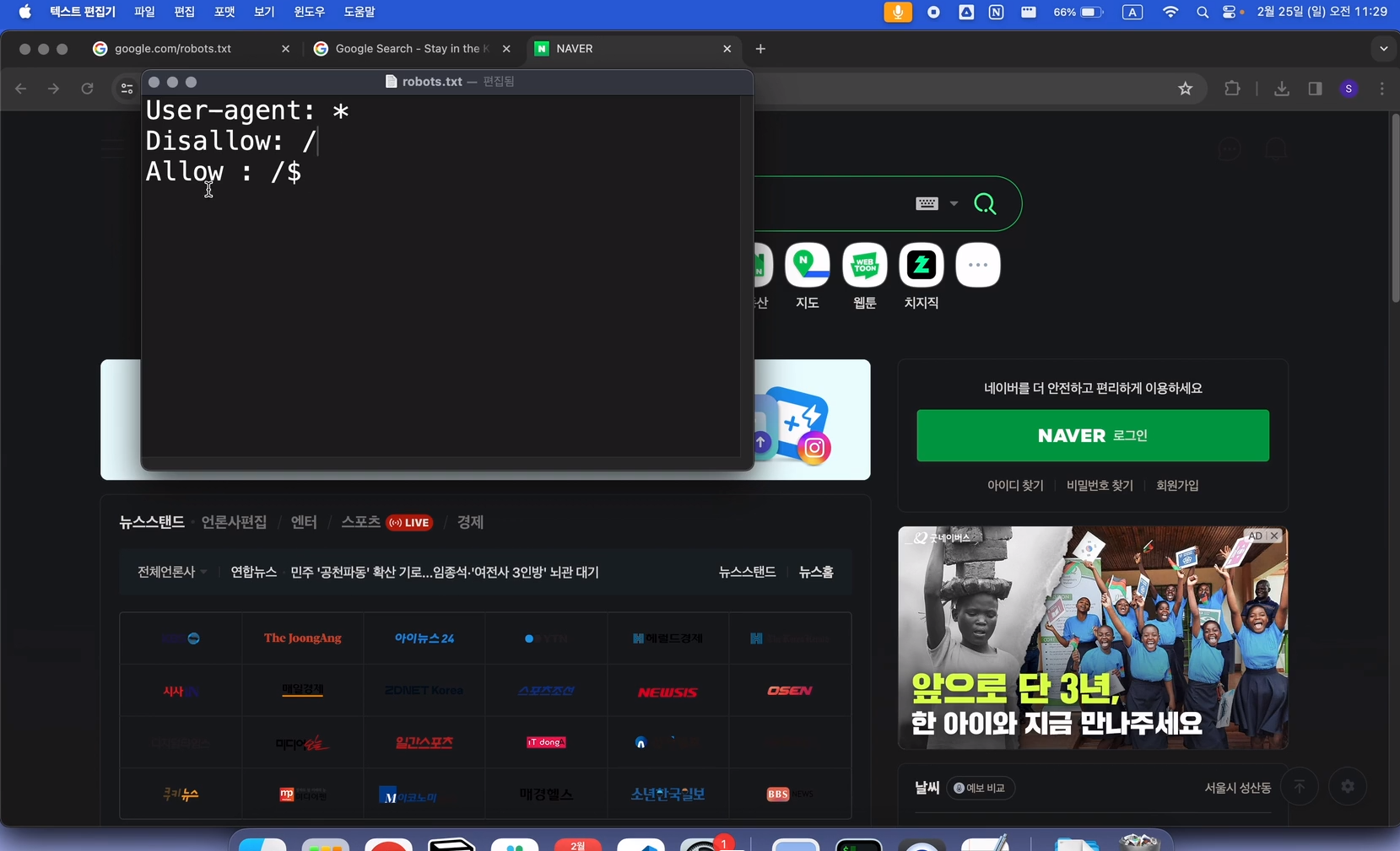
robots.txt 파일의 기본 구조
- User-agent: 특정 크롤러 또는 모든 크롤러(*)를 대상으로 지시어를 적용합니다.
- Allow: 크롤러가 접근할 수 있는 페이지 또는 디렉토리를 지정합니다.
- Disallow: 크롤러의 접근을 금지하는 페이지 또는 디렉토리를 지정합니다.

robots.txt의 중요성
- 검색 엔진 최적화(SEO): robots.txt 파일은 검색 엔진이 사이트의 어떤 부분을 인덱싱할지 결정하는 데 도움을 줍니다. 잘 구성된 robots.txt 파일은 SEO에 긍정적인 영향을 미칠 수 있습니다.
- 사이트 보호: 민감한 정보가 담긴 페이지나, 사용자에게 보여주고 싶지 않은 페이지를 검색 엔진 결과에서 제외시키는 데 중요한 역할을 합니다.
'이벤트' 카테고리의 다른 글
| 웹 크롤링 기초 강의ㅣ뉴스, 기차 예매, 여행 사이트 실습 [리뷰4] (0) | 2024.04.21 |
|---|---|
| 웹 크롤링 기초 강의ㅣ뉴스, 기차 예매, 여행 사이트 실습 [리뷰3] (0) | 2024.04.21 |
| 웹 크롤링 기초 강의ㅣ뉴스, 기차 예매, 여행 사이트 실습 [리뷰1] (0) | 2024.04.21 |
| [C 프로그래밍] 메타코드 강의 후기_(챕터 17 : 연산자, 챕터 18 : main 매개변수, 챕터 19 : gdb 디버거) (0) | 2024.03.31 |
| [C 프로그래밍] 메타코드 강의 후기_(챕터 15 : 함수 고급, 챕터 16 : 전처리기와 헤더 파일) (0) | 2024.03.31 |



